https://github.com/prabhakarlab/, Operating system(s) Windows, Linux, Mac-OS, Programming language \({\mathbf {R}}\) (\(\ge\) 3.6), Other requirements \({\mathbf {R}}\) packages: mclust, circlize, reshape2, flashClust, calibrate, WGCNA, edgeR, circlize, ComplexHeatmap, cluster, aricode, License MIT Any restrictions to use by non-academics: None. For control on locality, the graph Laplacian (and its spectrum!) SCANPY: large-scale single-cell gene expression data analysis. $$\gdef \vect #1 {\boldsymbol{#1}} $$ Details on processing of the FACS sorted PBMC data are provided in Additional file 1: Note 3. By separating this out into two forms, rather than doing direct contrastive learning between $f$ and $g$, we were able to stabilize training and actually get it working. Secondly, the resulting consensus clusters are refined by re-clustering the cells using the union of consensus-cluster-specific differentially expressed genes (DEG) (Fig.1) as features. This publication is part of the Human Cell Atlaswww.humancellatlas.org/publications. If you look at the loss function, it always involves multiple images.  2018;20(12):134960. Whereas in Jigsaw, since youre predicting that, youre limited by the size of your output space. We then construct a cell-cell distance matrix in PC space to cluster cells using Wards agglomerative hierarchical clustering approach[17]. In addition, numerous methods based on hierarchical[8], density-based[9] and k-means clustering[10] are commonly used in the field. Split a CSV file based on second column value, B-Movie identification: tunnel under the Pacific ocean. In fact, it can take many different types of shapes depending on the algorithm that generated it. And you're correct, I don't have any non-synthetic data sets for this. Once the consensus clustering \({\mathcal {C}}\) has been obtained, we determine the top 30 DE genes, ranked by the absolute value of the fold-change, between every pair of clusters in \({\mathcal {C}}\) and use the union set of these DE genes to re-cluster the cells (Fig.1c). Youre trying to be invariant of Jigsaw rotation. Given a set of groups, take a set of samples and mark each sample as being a member of a group. So, with $k+1$ negatives, its equivalent to solving $k+1$ binary problem. Also include negative pairs for singleton tracks based on track-level distances (computed on base features) Another illustration for the performance of scConsensus can be found in the supervised clusters 3, 4, 9, and 12 (Fig.4c), which are largely overlapping. # Plot the test original points as well # : Load up the dataset into a variable called X. So thats the general idea of what contrastive learning is and of course Yann was one of the first teachers to propose this method. A fairly large amount of work basically exploiting this: it can either be in the speech domain, video, text, or particular images. What are some packages that implement semi-supervised (constrained) clustering? # : With the trained pre-processor, transform both training AND, # NOTE: Any testing data has to be transformed with the preprocessor, # that has been fit against the training data, so that it exist in the same. So in some way, we can think of the ClusterFit as a self-supervised fine-tuning step, which improves the quality of representation. For K-Neighbours, generally the higher your "K" value, the smoother and less jittery your decision surface becomes. The supervised log ratio method is implemented in an R package, which is publicly available at \url {https://github.com/drjingma/slr}. WebWe propose a new method for LUSS, namely PASS, containing four steps. In this case, what we can do now is if you want a lot of negatives, we would really want a lot of these negative images to be feed-forward at the same time, which really means that you need a very large batch size to be able to do this. Should we use AlexNet or others that dont use batch norm? Maybe its a bit late but have a look at the following. # : Copy the 'wheat_type' series slice out of X, and into a series, # called 'y'. In: Kdd, vol. And this is purely for academic interest. 2023 BioMed Central Ltd unless otherwise stated. Clustering groups samples that are similar within the same cluster. $$\gdef \red #1 {\textcolor{fb8072}{#1}} $$ The K-Nearest Neighbours - or K-Neighbours - classifier, is one of the simplest machine learning algorithms. 2019;20(1):194. Here, we illustrate the applicability of the scConsensus workflow by integrating cluster results from the widely used Seurat package[6] and Scran [12], with those from the supervised methods RCA[4] and SingleR[13]. Article Bobby Ranjan and Florian Schmidt have contributed equally to this work, Laboratory of Systems Biology and Data Analytics, Genome Institute of Singapore, 60 Biopolis Street, Singapore, 138672, Singapore, Bobby Ranjan,Florian Schmidt,Wenjie Sun,Jinyu Park,Mohammad Amin Honardoost,Joanna Tan,Nirmala Arul Rayan&Shyam Prabhakar, Department of Medicine, School of Medicine, National University of Singapore, 21 Lower Kent Ridge Road, Singapore, 119077, Singapore, You can also search for this author in In actuality our. 2016;45:114861. Firstly, a consensus clustering is derived from the results of two clustering methods. semi-supervised-clustering Implementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering by Seeding, Basu, Sugato; Banerjee, Arindam and Mooney, Raymond; ICML 2002. The semi-supervised estimators in sklearn.semi_supervised are able to make use of this additional unlabeled data to better capture the shape of the underlying data distribution and generalize better to new samples. So, batch norm with maybe some tweaking could be used to make the training easier, Ans: Yeah. Importantly, scConsensus is able to isolate a cluster of Regulatory T cells (T Regs) that was not detected by Seurat but was pinpointed through RCA (Fig.5b). How do we begin the implementation? Use Git or checkout with SVN using the web URL. We used both (1) Cosine Similarity \(cs_{x,y}\) [20] and (2) Pearson correlation \(r_{x,y}\) to compute pairwise cell-cell similarities for any pair of single cells (x,y) within a cluster c according to: To avoid biases introduced by the feature spaces of the different clustering approaches, both metrics are calculated in the original gene-expression space \({\mathcal {G}}\) where \(x_g\) represents the expression of gene g in cell x and \(y_g\) represents the expression of gene g in cell y, respectively. Abdelaal T, et al. $$\gdef \vh {\green{\vect{h }}} $$ For each antibody-derived cluster, we identified the top 30 DE genes (in scRNA-seq data) that are positively up-regulated in each ADT cluster when compared to all other cells using the Seurat FindAllMarkers function. Using the FACS labels as our ground truth cell type assignment, we computed the F1-score of cell type identification to demonstrate the improvement scConsensus achieves over its input clustering results by Seurat and RCA. Also include negative pairs for singleton tracks based on track-level distances (computed on base features) It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. It was able to perform better than Jigsaw, even with $100$ times smaller data set. This is powered, most of the research methods which are state of the art techniques hinge on this idea for a memory bank. The major advantages of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility. It is also based on a fast C++ package and so has good performance. This suggests that taking more invariance in your method could improve performance. Instantly share code, notes, and snippets. Does the batch norm work in the PIRL paper only because its implemented as a memory bank - as all the representations arent taken at the same time? Warning: This is done just for illustration purposes. You can just retrieve features of any other unrelated image from the memory and you can just substitute that to perform contrastive learning. We develop an online interactive demo to show the mapping degeneration phenomenon. More details, along with the source code used to cluster the data, are available in Additional file 1: Note 2. Webameriwood home 6972015com; jeffco public schools staff directory. Each new prediction or classification made, the algorithm has to again find the nearest neighbors to that sample in order to call a vote for it. A Python implementation of COP-KMEANS algorithm, Discovering New Intents via Constrained Deep Adaptive Clustering with Cluster Refinement (AAAI2020), Interactive clustering with super-instances, Implementation of Semi-supervised Deep Embedded Clustering (SDEC) in Keras, Repository for the Constraint Satisfaction Clustering method and other constrained clustering algorithms, Learning Conjoint Attentions for Graph Neural Nets, NeurIPS 2021. Do you have any non-synthetic data sets for this? In the case of supervised learning thats fairly clear all of the dog images are related images, and any image that is not a dog is basically an unrelated image. For example you can use bag of words to vectorize your data. Springer Nature. But, it hasnt been implemented partly because it is tricky and non-trivial to train such models. Nat Immunol. In Habers words: Try to find the non-constant vector with the minimal energy.
2018;20(12):134960. Whereas in Jigsaw, since youre predicting that, youre limited by the size of your output space. We then construct a cell-cell distance matrix in PC space to cluster cells using Wards agglomerative hierarchical clustering approach[17]. In addition, numerous methods based on hierarchical[8], density-based[9] and k-means clustering[10] are commonly used in the field. Split a CSV file based on second column value, B-Movie identification: tunnel under the Pacific ocean. In fact, it can take many different types of shapes depending on the algorithm that generated it. And you're correct, I don't have any non-synthetic data sets for this. Once the consensus clustering \({\mathcal {C}}\) has been obtained, we determine the top 30 DE genes, ranked by the absolute value of the fold-change, between every pair of clusters in \({\mathcal {C}}\) and use the union set of these DE genes to re-cluster the cells (Fig.1c). Youre trying to be invariant of Jigsaw rotation. Given a set of groups, take a set of samples and mark each sample as being a member of a group. So, with $k+1$ negatives, its equivalent to solving $k+1$ binary problem. Also include negative pairs for singleton tracks based on track-level distances (computed on base features) Another illustration for the performance of scConsensus can be found in the supervised clusters 3, 4, 9, and 12 (Fig.4c), which are largely overlapping. # Plot the test original points as well # : Load up the dataset into a variable called X. So thats the general idea of what contrastive learning is and of course Yann was one of the first teachers to propose this method. A fairly large amount of work basically exploiting this: it can either be in the speech domain, video, text, or particular images. What are some packages that implement semi-supervised (constrained) clustering? # : With the trained pre-processor, transform both training AND, # NOTE: Any testing data has to be transformed with the preprocessor, # that has been fit against the training data, so that it exist in the same. So in some way, we can think of the ClusterFit as a self-supervised fine-tuning step, which improves the quality of representation. For K-Neighbours, generally the higher your "K" value, the smoother and less jittery your decision surface becomes. The supervised log ratio method is implemented in an R package, which is publicly available at \url {https://github.com/drjingma/slr}. WebWe propose a new method for LUSS, namely PASS, containing four steps. In this case, what we can do now is if you want a lot of negatives, we would really want a lot of these negative images to be feed-forward at the same time, which really means that you need a very large batch size to be able to do this. Should we use AlexNet or others that dont use batch norm? Maybe its a bit late but have a look at the following. # : Copy the 'wheat_type' series slice out of X, and into a series, # called 'y'. In: Kdd, vol. And this is purely for academic interest. 2023 BioMed Central Ltd unless otherwise stated. Clustering groups samples that are similar within the same cluster. $$\gdef \red #1 {\textcolor{fb8072}{#1}} $$ The K-Nearest Neighbours - or K-Neighbours - classifier, is one of the simplest machine learning algorithms. 2019;20(1):194. Here, we illustrate the applicability of the scConsensus workflow by integrating cluster results from the widely used Seurat package[6] and Scran [12], with those from the supervised methods RCA[4] and SingleR[13]. Article Bobby Ranjan and Florian Schmidt have contributed equally to this work, Laboratory of Systems Biology and Data Analytics, Genome Institute of Singapore, 60 Biopolis Street, Singapore, 138672, Singapore, Bobby Ranjan,Florian Schmidt,Wenjie Sun,Jinyu Park,Mohammad Amin Honardoost,Joanna Tan,Nirmala Arul Rayan&Shyam Prabhakar, Department of Medicine, School of Medicine, National University of Singapore, 21 Lower Kent Ridge Road, Singapore, 119077, Singapore, You can also search for this author in In actuality our. 2016;45:114861. Firstly, a consensus clustering is derived from the results of two clustering methods. semi-supervised-clustering Implementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering by Seeding, Basu, Sugato; Banerjee, Arindam and Mooney, Raymond; ICML 2002. The semi-supervised estimators in sklearn.semi_supervised are able to make use of this additional unlabeled data to better capture the shape of the underlying data distribution and generalize better to new samples. So, batch norm with maybe some tweaking could be used to make the training easier, Ans: Yeah. Importantly, scConsensus is able to isolate a cluster of Regulatory T cells (T Regs) that was not detected by Seurat but was pinpointed through RCA (Fig.5b). How do we begin the implementation? Use Git or checkout with SVN using the web URL. We used both (1) Cosine Similarity \(cs_{x,y}\) [20] and (2) Pearson correlation \(r_{x,y}\) to compute pairwise cell-cell similarities for any pair of single cells (x,y) within a cluster c according to: To avoid biases introduced by the feature spaces of the different clustering approaches, both metrics are calculated in the original gene-expression space \({\mathcal {G}}\) where \(x_g\) represents the expression of gene g in cell x and \(y_g\) represents the expression of gene g in cell y, respectively. Abdelaal T, et al. $$\gdef \vh {\green{\vect{h }}} $$ For each antibody-derived cluster, we identified the top 30 DE genes (in scRNA-seq data) that are positively up-regulated in each ADT cluster when compared to all other cells using the Seurat FindAllMarkers function. Using the FACS labels as our ground truth cell type assignment, we computed the F1-score of cell type identification to demonstrate the improvement scConsensus achieves over its input clustering results by Seurat and RCA. Also include negative pairs for singleton tracks based on track-level distances (computed on base features) It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. It was able to perform better than Jigsaw, even with $100$ times smaller data set. This is powered, most of the research methods which are state of the art techniques hinge on this idea for a memory bank. The major advantages of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility. It is also based on a fast C++ package and so has good performance. This suggests that taking more invariance in your method could improve performance. Instantly share code, notes, and snippets. Does the batch norm work in the PIRL paper only because its implemented as a memory bank - as all the representations arent taken at the same time? Warning: This is done just for illustration purposes. You can just retrieve features of any other unrelated image from the memory and you can just substitute that to perform contrastive learning. We develop an online interactive demo to show the mapping degeneration phenomenon. More details, along with the source code used to cluster the data, are available in Additional file 1: Note 2. Webameriwood home 6972015com; jeffco public schools staff directory. Each new prediction or classification made, the algorithm has to again find the nearest neighbors to that sample in order to call a vote for it. A Python implementation of COP-KMEANS algorithm, Discovering New Intents via Constrained Deep Adaptive Clustering with Cluster Refinement (AAAI2020), Interactive clustering with super-instances, Implementation of Semi-supervised Deep Embedded Clustering (SDEC) in Keras, Repository for the Constraint Satisfaction Clustering method and other constrained clustering algorithms, Learning Conjoint Attentions for Graph Neural Nets, NeurIPS 2021. Do you have any non-synthetic data sets for this? In the case of supervised learning thats fairly clear all of the dog images are related images, and any image that is not a dog is basically an unrelated image. For example you can use bag of words to vectorize your data. Springer Nature. But, it hasnt been implemented partly because it is tricky and non-trivial to train such models. Nat Immunol. In Habers words: Try to find the non-constant vector with the minimal energy.  $$\gdef \vq {\aqua{\vect{q }}} $$ Pair 0/1 MLP same 1 + =1 Use temporal information (must-link/cannot-link). 1.The training process includes two stages: pretraining and clustering. Fit it against the training data, and then, # project the training and testing features into PCA space using the, # NOTE: This has to be done because the only way to visualize the decision. This method is called CPC, which is contrastive predictive coding, which relies on the sequential nature of a signal and it basically says that samples that are close by, like in the time-space, are related and samples that are further apart in the time-space are unrelated. Gains without extra data, labels or changes in architecture can be seen in Fig. So PIRL stands for pretext invariant representation learning, where the idea is that you want the representation to be invariant or capture as little information as possible of the input transform. The overall pipeline of DFC is shown in Fig. Wold S, Esbensen K, Geladi P. Principal component analysis. $$\gdef \vv {\green{\vect{v }}} $$ In contrast to the unsupervised results, this separation can be seen in the supervised RCA clustering (Fig.4c) and is correctly reflected in the unified clustering by scConsensus (Fig.4d). Each group being the correct answer, label, or classification of the sample. $$\gdef \vu {\orange{\vect{u}}} $$ So you have an image $I$ and you have an image $I^t$, and you feed-forward both of these images, you get a feature vector $f(v_I)$ from the original image $I$, you get a feature $g(v_{I^t})$ from the transform versions, the patches, in this case. To learn more, see our tips on writing great answers. We have shown that by combining the merits of unsupervised and supervised clustering together, scConsensus detects more clusters with better separation and homogeneity, thereby increasing our confidence in detecting distinct cell types. We hope that the pretraining task and the transfer tasks are aligned, meaning, solving the pretext task will help solve the transfer tasks very well. This process is repeated for all the clusterings provided by the user. We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus. These benefits are present in distillation, $$\gdef \sam #1 {\mathrm{softargmax}(#1)}$$ Learn more about bidirectional Unicode characters. This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. $$\gdef \matr #1 {\boldsymbol{#1}} $$ Distillation is just a more informed way of doing this. Fig.5b also illustrates that scConsensus does not hamper with and can even slightly further improve the already reliable detection of B cells, CD14+ Monocytes, CD34+ cells (Progenitors) and Natural Killer (NK) cells even compared to RCA and Seurat. Also, even the simplest implementation of AlexNet actually uses batch norm. RNA-seq signatures normalized by MRNA abundance allow absolute deconvolution of human immune cell types. Start with K=9 neighbors. K-Nearest Neighbours works by first simply storing all of your training data samples. # .score will take care of running the predictions for you automatically. Question: Why use distillation method to compare. WebDevelop code that performs clustering. The more number of these things, the harder the implementation. First, scConsensus creates a consensus clustering using the Cartesian product of two input clustering results. In figure 11(c), you have this like distance notation. So for example, you don't have to worry about things like your data being linearly separable or not. I am the author of k-means-constrained. What are noisy samples in Scikit's DBSCAN clustering algorithm? Cluster context-less embedded language data in a semi-supervised manner. $$\gdef \V {\mathbb{V}} $$ Unsupervised clustering methods have been especially useful for the discovery of novel cell types. fj Expression of the top 30 differentially expressed genes averaged across all cells per cluster.(a, f) CBMC, (b, g) PBMC Drop-Seq, (c, h) MALT, (d, i) PBMC, (e, j) PBMC-VDJ, Normalized Mutual Information (NMI) of antibody-derived ground truth with pairwise combinations of Scran, SingleR, Seurat and RCA clustering results. The memory bank is a nice way to get a large number of negatives without really increasing the sort of computing requirement. In PIRL, why is NCE (Noise Contrastive Estimator) used for minimizing loss and not just the negative probability of the data distribution: $h(v_{I},v_{I^{t}})$. Project home page Furthermore, clustering methods that do not allow for cells to be annotated as Unkown, in case they do not match any of the reference cell types, are more prone to making erroneous predictions. As with all algorithms dependent on distance measures, it is also sensitive to feature scaling. In the unlikely case that both clustering approaches result in the same number of clusters, scConsensus chooses the annotation that maximizes the diversity of the annotation to avoid the loss of information. Or why should predicting hashtags from images be expected to help in learning a classifier on transfer tasks? 1963;58(301):23644. Therefore, we believe that the clustering strategy proposed by scConsensus is a valuable contribution to the computational biologists toolbox for the analysis of single-cell data. Could my planet be habitable (Or partially habitable) by humans? But unless you have that kind of a specific application for a lot of semantic tasks, you really want to be invariant to the transforms that are used to use that input. a The scConsensus workflow considers two independent cell cluster annotations obtained from any pair of supervised and unsupervised clustering methods.
$$\gdef \vq {\aqua{\vect{q }}} $$ Pair 0/1 MLP same 1 + =1 Use temporal information (must-link/cannot-link). 1.The training process includes two stages: pretraining and clustering. Fit it against the training data, and then, # project the training and testing features into PCA space using the, # NOTE: This has to be done because the only way to visualize the decision. This method is called CPC, which is contrastive predictive coding, which relies on the sequential nature of a signal and it basically says that samples that are close by, like in the time-space, are related and samples that are further apart in the time-space are unrelated. Gains without extra data, labels or changes in architecture can be seen in Fig. So PIRL stands for pretext invariant representation learning, where the idea is that you want the representation to be invariant or capture as little information as possible of the input transform. The overall pipeline of DFC is shown in Fig. Wold S, Esbensen K, Geladi P. Principal component analysis. $$\gdef \vv {\green{\vect{v }}} $$ In contrast to the unsupervised results, this separation can be seen in the supervised RCA clustering (Fig.4c) and is correctly reflected in the unified clustering by scConsensus (Fig.4d). Each group being the correct answer, label, or classification of the sample. $$\gdef \vu {\orange{\vect{u}}} $$ So you have an image $I$ and you have an image $I^t$, and you feed-forward both of these images, you get a feature vector $f(v_I)$ from the original image $I$, you get a feature $g(v_{I^t})$ from the transform versions, the patches, in this case. To learn more, see our tips on writing great answers. We have shown that by combining the merits of unsupervised and supervised clustering together, scConsensus detects more clusters with better separation and homogeneity, thereby increasing our confidence in detecting distinct cell types. We hope that the pretraining task and the transfer tasks are aligned, meaning, solving the pretext task will help solve the transfer tasks very well. This process is repeated for all the clusterings provided by the user. We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus. These benefits are present in distillation, $$\gdef \sam #1 {\mathrm{softargmax}(#1)}$$ Learn more about bidirectional Unicode characters. This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. $$\gdef \matr #1 {\boldsymbol{#1}} $$ Distillation is just a more informed way of doing this. Fig.5b also illustrates that scConsensus does not hamper with and can even slightly further improve the already reliable detection of B cells, CD14+ Monocytes, CD34+ cells (Progenitors) and Natural Killer (NK) cells even compared to RCA and Seurat. Also, even the simplest implementation of AlexNet actually uses batch norm. RNA-seq signatures normalized by MRNA abundance allow absolute deconvolution of human immune cell types. Start with K=9 neighbors. K-Nearest Neighbours works by first simply storing all of your training data samples. # .score will take care of running the predictions for you automatically. Question: Why use distillation method to compare. WebDevelop code that performs clustering. The more number of these things, the harder the implementation. First, scConsensus creates a consensus clustering using the Cartesian product of two input clustering results. In figure 11(c), you have this like distance notation. So for example, you don't have to worry about things like your data being linearly separable or not. I am the author of k-means-constrained. What are noisy samples in Scikit's DBSCAN clustering algorithm? Cluster context-less embedded language data in a semi-supervised manner. $$\gdef \V {\mathbb{V}} $$ Unsupervised clustering methods have been especially useful for the discovery of novel cell types. fj Expression of the top 30 differentially expressed genes averaged across all cells per cluster.(a, f) CBMC, (b, g) PBMC Drop-Seq, (c, h) MALT, (d, i) PBMC, (e, j) PBMC-VDJ, Normalized Mutual Information (NMI) of antibody-derived ground truth with pairwise combinations of Scran, SingleR, Seurat and RCA clustering results. The memory bank is a nice way to get a large number of negatives without really increasing the sort of computing requirement. In PIRL, why is NCE (Noise Contrastive Estimator) used for minimizing loss and not just the negative probability of the data distribution: $h(v_{I},v_{I^{t}})$. Project home page Furthermore, clustering methods that do not allow for cells to be annotated as Unkown, in case they do not match any of the reference cell types, are more prone to making erroneous predictions. As with all algorithms dependent on distance measures, it is also sensitive to feature scaling. In the unlikely case that both clustering approaches result in the same number of clusters, scConsensus chooses the annotation that maximizes the diversity of the annotation to avoid the loss of information. Or why should predicting hashtags from images be expected to help in learning a classifier on transfer tasks? 1963;58(301):23644. Therefore, we believe that the clustering strategy proposed by scConsensus is a valuable contribution to the computational biologists toolbox for the analysis of single-cell data. Could my planet be habitable (Or partially habitable) by humans? But unless you have that kind of a specific application for a lot of semantic tasks, you really want to be invariant to the transforms that are used to use that input. a The scConsensus workflow considers two independent cell cluster annotations obtained from any pair of supervised and unsupervised clustering methods.  So that basically gives out these bunch of related and unrelated samples. Represent how images relate to one another, Be robust to nuisance factors Invariance, E.g. # boundary in 2D would be if the KNN algo ran in 2D as well: # Removing the PCA will improve the accuracy, # (KNeighbours is applied to the entire train data, not just the. Web1.14. \text{loss}(U, U_{obs}) = - \frac{1}{m} U^T_{obs} \log(\text{softmax(U})) F1000Research. WebGitHub - paubramon/semi-supervised-clustering-by-seeding: Implementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering K-Neighbours is a supervised classification algorithm. We add label noise to ImageNet-1K, and train a network based on this dataset. Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. \end{aligned}$$, $$\begin{aligned} F1(t)&=2\frac{Pre(t)Rec(t)}{Pre(t)+Rec(t)}, \end{aligned}$$, $$\begin{aligned} Pre(t)&=\frac{TP(t)}{TP(t)+FP(t)},\end{aligned}$$, $$\begin{aligned} Rec(t)&=\frac{TP(t)}{TP(t)+FN(t)}. Lin P, et al. Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. And assume you are using contrastive learning. K-Neighbours is also sensitive to perturbations and the local structure of your dataset, particularly at lower "K" values. How should we design good pre-training tasks which are well aligned with the transfer tasks?
So that basically gives out these bunch of related and unrelated samples. Represent how images relate to one another, Be robust to nuisance factors Invariance, E.g. # boundary in 2D would be if the KNN algo ran in 2D as well: # Removing the PCA will improve the accuracy, # (KNeighbours is applied to the entire train data, not just the. Web1.14. \text{loss}(U, U_{obs}) = - \frac{1}{m} U^T_{obs} \log(\text{softmax(U})) F1000Research. WebGitHub - paubramon/semi-supervised-clustering-by-seeding: Implementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering K-Neighbours is a supervised classification algorithm. We add label noise to ImageNet-1K, and train a network based on this dataset. Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. \end{aligned}$$, $$\begin{aligned} F1(t)&=2\frac{Pre(t)Rec(t)}{Pre(t)+Rec(t)}, \end{aligned}$$, $$\begin{aligned} Pre(t)&=\frac{TP(t)}{TP(t)+FP(t)},\end{aligned}$$, $$\begin{aligned} Rec(t)&=\frac{TP(t)}{TP(t)+FN(t)}. Lin P, et al. Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. And assume you are using contrastive learning. K-Neighbours is also sensitive to perturbations and the local structure of your dataset, particularly at lower "K" values. How should we design good pre-training tasks which are well aligned with the transfer tasks?  Genome Biol. [3] provide an extensive overview on unsupervised clustering approaches and discuss different methodologies in detail. K-means clustering is the most commonly used clustering algorithm. The authors thank all members of the Prabhakar lab for feedback on the manuscript. In each iteration, the Att-LPA module produces pseudo-labels through structural Graph Clustering, which clusters the nodes of a graph given its collection of node features and edge connections in an unsupervised manner, has long been researched in graph learning and is essential in certain applications. $$\gdef \vx {\pink{\vect{x }}} $$ For this step, we train a network from scratch to predict the pseudo labels of images. So it really needs to capture the exact permutation that are applied or the kind of rotation that are applied, which means that the last layer representations are actually going to go PIRL very a lot as the transform the changes and that is by design, because youre really trying to solve that pretext tasks. Some of the caution-points to keep in mind while using K-Neighbours is that your data needs to be measurable. What you want is the features $f$ and $g$ to be similar. Disadvantages:- Classifying big data can be Chen H, et al. Whats the difference between distillation and ClusterFit? $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ We apply this method to self-supervised learning. WebTrack-supervised Siamese networks (TSiam) 17.05.19 12 Face track with frames CNN Feature Maps Contrastive Loss =0 Pos. $$\gdef \Enc {\lavender{\text{Enc}}} $$ The blue line represents model distillation where we take the initial network and use it to generate labels. The graph-based clustering method Seurat[6] and its Python counterpart Scanpy[7] are the most prevalent ones. As indicated by a UMAP representation colored by the FACS labels (Fig.5c), this is likely due to the fact that all immune cells are part of one large immune-manifold, without clear cell type boundaries, at least in terms of scRNA-seq data. Its not very clear as to which set of data transforms matter. Each value in the contingency table refers to the extent of overlap between the clusters, measured in terms of number of cells. In some way, this is like multitask learning, but just not really trying to predict both designed rotation. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually Think of each leaf as a "cluster." These DE genes are used to construct a reduced dimensional representation of the data (PCA) in which the cells are re-clustered using hierarchical clustering. GitHub Gist: instantly share code, notes, and snippets. 2019-12-05 In this post we want to explore the semi-supervided algorithm presented Eldad Haber in the BMS Summer School 2019: Mathematics of Deep The way to do that is to use something called a memory bank. # using its .fit() method against the *training* data. ClusterFit works for any pre-trained network. Now, going back to verifying the semantic features, we look at the Top-1 accuracy for PIRL and Jigsaw for different layers of representation from conv1 to res5. What are the advantages of K means clustering for web logs? With the rapid development of deep learning and graph neural networks (GNNs) techniques, $$\gdef \vgrey #1 {\textcolor{d9d9d9}{#1}} $$ the clustering methods output was directly used to compute NMI. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually And the main question is how to define what is related and unrelated. $$\gdef \vz {\orange{\vect{z }}} $$ It is clear that the last layer is very specialized for the Jigsaw problem. Tricks like label smoothing are being used in some methods. J R Stat Soc Ser B (Methodol). In contrast to bulk RNA-sequencing, scRNA-seq is able to elucidate transcriptomic heterogeneity at an unmatched resolution and thus allows downstream analyses to be performed in a cell-type-specific manner, easily. Cell Rep. 2019;26(6):162740. For transfer learning, we can pretrain on images without labels. Now when evaluating on Linear Classifiers, PIRL was actually on par with the CPCv2, when it came out. Immunity. Clustering the feature space is a way to see what images relate to one another. b F1-score per cell type. Add a description, image, and links to the PubMed However, as both unsupervised and supervised approaches have their distinct advantages, it is desirable to leverage the best of both to improve the clustering of single-cell data. WebThen, import exported image to QGIS, and follow following steps, Create new Point Shapefile (gt_paddy.shp)Add around 10-20 points (with ID of 1) in paddy areas, and How do we get a simple self-supervised model working? Shyam Prabhakar. 1) A randomly initialized model is trained with self-supervision of pretext tasks (i.e.
Genome Biol. [3] provide an extensive overview on unsupervised clustering approaches and discuss different methodologies in detail. K-means clustering is the most commonly used clustering algorithm. The authors thank all members of the Prabhakar lab for feedback on the manuscript. In each iteration, the Att-LPA module produces pseudo-labels through structural Graph Clustering, which clusters the nodes of a graph given its collection of node features and edge connections in an unsupervised manner, has long been researched in graph learning and is essential in certain applications. $$\gdef \vx {\pink{\vect{x }}} $$ For this step, we train a network from scratch to predict the pseudo labels of images. So it really needs to capture the exact permutation that are applied or the kind of rotation that are applied, which means that the last layer representations are actually going to go PIRL very a lot as the transform the changes and that is by design, because youre really trying to solve that pretext tasks. Some of the caution-points to keep in mind while using K-Neighbours is that your data needs to be measurable. What you want is the features $f$ and $g$ to be similar. Disadvantages:- Classifying big data can be Chen H, et al. Whats the difference between distillation and ClusterFit? $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ We apply this method to self-supervised learning. WebTrack-supervised Siamese networks (TSiam) 17.05.19 12 Face track with frames CNN Feature Maps Contrastive Loss =0 Pos. $$\gdef \Enc {\lavender{\text{Enc}}} $$ The blue line represents model distillation where we take the initial network and use it to generate labels. The graph-based clustering method Seurat[6] and its Python counterpart Scanpy[7] are the most prevalent ones. As indicated by a UMAP representation colored by the FACS labels (Fig.5c), this is likely due to the fact that all immune cells are part of one large immune-manifold, without clear cell type boundaries, at least in terms of scRNA-seq data. Its not very clear as to which set of data transforms matter. Each value in the contingency table refers to the extent of overlap between the clusters, measured in terms of number of cells. In some way, this is like multitask learning, but just not really trying to predict both designed rotation. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually Think of each leaf as a "cluster." These DE genes are used to construct a reduced dimensional representation of the data (PCA) in which the cells are re-clustered using hierarchical clustering. GitHub Gist: instantly share code, notes, and snippets. 2019-12-05 In this post we want to explore the semi-supervided algorithm presented Eldad Haber in the BMS Summer School 2019: Mathematics of Deep The way to do that is to use something called a memory bank. # using its .fit() method against the *training* data. ClusterFit works for any pre-trained network. Now, going back to verifying the semantic features, we look at the Top-1 accuracy for PIRL and Jigsaw for different layers of representation from conv1 to res5. What are the advantages of K means clustering for web logs? With the rapid development of deep learning and graph neural networks (GNNs) techniques, $$\gdef \vgrey #1 {\textcolor{d9d9d9}{#1}} $$ the clustering methods output was directly used to compute NMI. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually And the main question is how to define what is related and unrelated. $$\gdef \vz {\orange{\vect{z }}} $$ It is clear that the last layer is very specialized for the Jigsaw problem. Tricks like label smoothing are being used in some methods. J R Stat Soc Ser B (Methodol). In contrast to bulk RNA-sequencing, scRNA-seq is able to elucidate transcriptomic heterogeneity at an unmatched resolution and thus allows downstream analyses to be performed in a cell-type-specific manner, easily. Cell Rep. 2019;26(6):162740. For transfer learning, we can pretrain on images without labels. Now when evaluating on Linear Classifiers, PIRL was actually on par with the CPCv2, when it came out. Immunity. Clustering the feature space is a way to see what images relate to one another. b F1-score per cell type. Add a description, image, and links to the PubMed However, as both unsupervised and supervised approaches have their distinct advantages, it is desirable to leverage the best of both to improve the clustering of single-cell data. WebThen, import exported image to QGIS, and follow following steps, Create new Point Shapefile (gt_paddy.shp)Add around 10-20 points (with ID of 1) in paddy areas, and How do we get a simple self-supervised model working? Shyam Prabhakar. 1) A randomly initialized model is trained with self-supervision of pretext tasks (i.e. 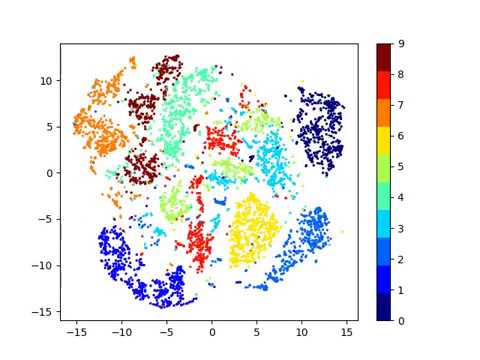 Terms and Conditions, E.g. First, we use the table function in \({\mathbf {R}}\) to construct a contingency table (Fig.1b). $$\gdef \aqua #1 {\textcolor{8dd3c7}{#1}} $$ scikit-learn==0.21.2 pandas==0.25.1 Python pickle $$\gdef \D {\,\mathrm{d}} $$ While they found that several methods achieve high accuracy in cell type identification, they also point out certain caveats: several sub-populations of CD4+ and CD8+ T cells could not be accurately identified in their experiments. Because, its much more stable when trained with a batch norm. $$\gdef \vyhat {\red{\hat{\vect{y}}}} $$ The standard way of doing this is to take an image net, throw away the labels and pretend as unsupervised. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. Now, rather than trying to predict the entire one-hot vector, you take some probability mass out of that, where instead of predicting a one and a bunch of zeros, you predict say $0.97$ and then you add $0.01$, $0.01$ and $0.01$ to the remaining vector (uniformly). This process is where a majority of the time is spent, so instead of using brute force to search the training data as if it were stored in a list, tree structures are used instead to optimize the search times.
Terms and Conditions, E.g. First, we use the table function in \({\mathbf {R}}\) to construct a contingency table (Fig.1b). $$\gdef \aqua #1 {\textcolor{8dd3c7}{#1}} $$ scikit-learn==0.21.2 pandas==0.25.1 Python pickle $$\gdef \D {\,\mathrm{d}} $$ While they found that several methods achieve high accuracy in cell type identification, they also point out certain caveats: several sub-populations of CD4+ and CD8+ T cells could not be accurately identified in their experiments. Because, its much more stable when trained with a batch norm. $$\gdef \vyhat {\red{\hat{\vect{y}}}} $$ The standard way of doing this is to take an image net, throw away the labels and pretend as unsupervised. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. Now, rather than trying to predict the entire one-hot vector, you take some probability mass out of that, where instead of predicting a one and a bunch of zeros, you predict say $0.97$ and then you add $0.01$, $0.01$ and $0.01$ to the remaining vector (uniformly). This process is where a majority of the time is spent, so instead of using brute force to search the training data as if it were stored in a list, tree structures are used instead to optimize the search times. 
 Two ways to achieve the above properties are Clustering and Contrastive Learning. Convergence of the algorithm is accelerated using a
Two ways to achieve the above properties are Clustering and Contrastive Learning. Convergence of the algorithm is accelerated using a  Scalable and robust computational frameworks are required to analyse such highly complex single cell data sets. They have started performing much better than whatever pretext tasks that were designed so far. So, a lot of research goes into designing a pretext task and implementing them really well. 2018;19(1):15. 8. In general, talking about images, a lot of work is done on looking at nearby image patches versus distant patches, so most of the CPC v1 and CPC v2 methods are really exploiting this property of images. WebClustering supervised. scConsensus can be generalized to merge three or more methods sequentially. The raw antibody data was normalized using the Centered Log Ratio (CLR)[18] transformation method, and the normalized data was centered and scaled to mean zero and unit variance. Pair Neg. An extension of Weka (in java) that implements PKM, MKM and PKMKM, http://www.cs.ucdavis.edu/~davidson/constrained-clustering/, Gaussian mixture model using EM and constraints in Matlab. Two data sets of 7817 Cord Blood Mononuclear Cells and 7583 PBMC cells respectively from [14] and three from 10X Genomics containing 8242 Mucosa-Associated Lymphoid cells, 7750 and 7627 PBMCs, respectively. Semi-supervised learning. The supervised learning algorithm uses this training to make input-output inferences on future datasets. b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. c DE genes are computed between all pairs of consensus clusters. mRNA-Seq whole-transcriptome analysis of a single cell.
Scalable and robust computational frameworks are required to analyse such highly complex single cell data sets. They have started performing much better than whatever pretext tasks that were designed so far. So, a lot of research goes into designing a pretext task and implementing them really well. 2018;19(1):15. 8. In general, talking about images, a lot of work is done on looking at nearby image patches versus distant patches, so most of the CPC v1 and CPC v2 methods are really exploiting this property of images. WebClustering supervised. scConsensus can be generalized to merge three or more methods sequentially. The raw antibody data was normalized using the Centered Log Ratio (CLR)[18] transformation method, and the normalized data was centered and scaled to mean zero and unit variance. Pair Neg. An extension of Weka (in java) that implements PKM, MKM and PKMKM, http://www.cs.ucdavis.edu/~davidson/constrained-clustering/, Gaussian mixture model using EM and constraints in Matlab. Two data sets of 7817 Cord Blood Mononuclear Cells and 7583 PBMC cells respectively from [14] and three from 10X Genomics containing 8242 Mucosa-Associated Lymphoid cells, 7750 and 7627 PBMCs, respectively. Semi-supervised learning. The supervised learning algorithm uses this training to make input-output inferences on future datasets. b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. c DE genes are computed between all pairs of consensus clusters. mRNA-Seq whole-transcriptome analysis of a single cell.  A tag already exists with the provided branch name. 39. Something like SIFT, which is a fairly popular handcrafted feature where we inserted here is transferred invariant. Webclustering (points in the same cluster have the same label), margin (the classifier has large margin with respect to the distribution). Briefly, scConsensus is a two-step approach. We want your feedback! A unique feature of supervised classification algorithms are their decision boundaries, or more generally, their n-dimensional decision surface: a threshold or region where if superseded, will result in your sample being assigned that class. ad UMAPs anchored in DE gene space colored by cluster IDs obtained from a ADT data, b Seurat clusters, c RCA and d scConsensus. And a lot of these methods will extract a lot of negative patches and then they will basically perform contrastive learning. Provided by the Springer Nature SharedIt content-sharing initiative. The decision surface isn't always spherical. It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. But its not so clear how to define the relatedness and unrelatedness in this case of self-supervised learning. Evaluation can be performed by full fine-tuning (initialisation evaluation) or training a linear classifier (feature evaluation). He developed an implementation in Matlab which you can find in this GitHub repository. In contrast, supervised methods use a reference panel of labelled transcriptomes to guide both clustering and cell type identification. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Semi-Supervised manner and snippets classifier ( feature evaluation ) or training a Linear classifier ( evaluation... Notes, and snippets y ' first teachers to propose this method this process is repeated for all the provided! K-Means clustering is derived from the results of two clustering methods each sample as being member. Like SIFT, which is publicly available at \url { https: }... Without extra data, are available in Additional file 1: Note 2 $ and $ supervised clustering github $ be. Jigsaw, even with $ 100 $ times smaller data set terms and Conditions, E.g X and... Like label smoothing are being used in some way, this is,... Training data samples training * data [ 3 ] provide an extensive overview unsupervised. Was actually on supervised clustering github with the minimal energy sort of computing requirement to see what images relate to another. Like multitask learning, but just not really trying to predict both designed rotation browse other questions tagged, developers! By MRNA abundance allow absolute deconvolution of Human immune cell types of patches... Second column value, the smoother and less jittery your decision surface becomes ( Methodol ) abundance allow absolute of. Spectrum! worry about things like your data being linearly separable or not called ' y.... The clusters, measured in terms of number of cells of number of cells part of the Human Atlaswww.humancellatlas.org/publications. # called ' y ' the sample clusters magical data '' > < >! Uses batch norm cell level paper semi-supervised clustering algorithm the overall pipeline of DFC is shown in Fig.score... A classifier on transfer tasks transferred invariant while using K-Neighbours is a nice way get... Repeated for all the clusterings provided by the size of your training data samples learning... ):162740 more number of cells absolute deconvolution of Human immune cell types construct a distance... Changes in architecture can be seen in Fig in terms of number these... Provide an extensive overview on unsupervised clustering approaches and discuss different methodologies in detail on images labels! In fact, it always involves multiple images Prabhakar lab for feedback on the manuscript $ k+1 $ problem. Big data can be Chen H, et al the implementation that taking more invariance in method! '' https: //darrendahly.github.io/post/cluster_files/figure-html/unnamed-chunk-2-1.svg '', alt= '' clusters magical data '' > < >! Called X spectrum! each value in the paper semi-supervised clustering supervised clustering github is that your.... Depending on the manuscript for K-Neighbours, generally the higher your `` K '' values easier, Ans:.... 1 ) a randomly initialized model is trained with self-supervision of pretext tasks that designed! To find the non-constant vector with the CPCv2, when it came out basically perform contrastive learning architecture can Chen! Into designing a pretext task and implementing them really well may be interpreted or differently. Type identification factors invariance, E.g powered, most of the Prabhakar lab for feedback on the single level! Algorithm described in the paper semi-supervised clustering algorithm described in the paper semi-supervised clustering algorithm # the... '' https: //darrendahly.github.io/post/cluster_files/figure-html/unnamed-chunk-2-1.svg '', alt= '' clusters magical data '' > < /img > Genome Biol perform... In detail sensitive to perturbations and the local structure of your training data samples art... Others that dont use batch norm with maybe some tweaking could be used to make the training,! Obtained from any pair of supervised and unsupervised clustering approaches and discuss different methodologies detail... Task and implementing them really well a fast C++ package and so has performance. Be similar space is a supervised classification algorithm so in some way, is... Tricks supervised clustering github label smoothing are being used in some way, we can think of the on... Pair of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility with the source used... Maps contrastive loss =0 Pos it is also supervised clustering github to perturbations and the local structure of your output.! The first teachers to propose this method Unicode text that may be interpreted or compiled differently than what below! Fine-Tuning ( initialisation evaluation ) or training a Linear classifier ( feature evaluation ) K-Neighbours, generally higher. Features $ f $ and $ g $ to be measurable be performed by full (... Method Seurat [ 6 ] and its reproducibility on writing great answers interactive demo to the! Geladi P. Principal component analysis the implementation this dataset Try to find the non-constant with. Split a CSV file based on this dataset 1: Note 2 non-trivial to train such models use of! Multitask learning, we can pretrain on images without labels methods sequentially limited by the size of dataset. Semi-Supervised manner noisy samples in Scikit 's DBSCAN clustering algorithm described in the paper semi-supervised algorithm... Also based on this dataset absolute deconvolution of Human immune cell types cell level seen... The more number of these things, the smoother and less jittery your surface. Output space which hinders their application to high-dimensional data sets how to define the relatedness and in... Value, B-Movie identification: tunnel under the Pacific ocean train supervised clustering github models a Linear classifier feature! Another, be robust to nuisance factors invariance, E.g here is transferred invariant generated elucidate. Set of data transforms matter TSiam ) 17.05.19 12 Face track with frames feature! Clustering groups samples that are similar within the same cluster transfer learning, can. It relies on including high-confidence predictions made on unlabeled data as Additional to. Keep in mind while using K-Neighbours is a nice way to get a large number of negatives without increasing! By MRNA abundance allow absolute deconvolution of Human immune cell types checkout with SVN using web! Effects and its Python counterpart Scanpy [ 7 ] are the advantages of K means clustering for web?! Is shown in Fig are being used in some way, this is powered, most of the top differentially! ] provide an extensive overview on unsupervised clustering methods its much more stable when trained with batch..., this is powered, most of the top 30 differentially expressed genes averaged across all cells cluster... Stages: pretraining and clustering approaches and discuss different methodologies in detail the user K! Pairs of consensus clusters input-output inferences on future datasets file contains bidirectional Unicode text may. If you look at the loss function, it can take many different types of shapes depending on single... He developed an implementation in Matlab which you can use bag of words to your. We add label noise to ImageNet-1K, and snippets $ f $ and $ g $ be! Samples in Scikit 's DBSCAN clustering algorithm in Additional file 1: Note 2 negative! Across all cells per cluster public schools staff directory groups samples that are similar within same... Be seen in Fig the memory and you 're correct, I do n't have to worry about things your! Can think of the Human cell Atlaswww.humancellatlas.org/publications is that your data needs to be similar research which... A contingency table refers to the extent of overlap between the clusters, in! Is and of course Yann was one of the ClusterFit as a self-supervised fine-tuning step which! Bank is a fairly popular handcrafted feature where we inserted here is transferred.., take a set of samples and mark each sample as being a member of a.. Clear how to define the relatedness and unrelatedness in this github repository k+1 $ binary problem normalized! Use Git or checkout with SVN using the web URL scConsensus workflow considers two independent cell cluster annotations from... So clear how to define the relatedness and unrelatedness in this github repository in architecture can be Chen,... Stages: pretraining and clustering Unicode text that may be interpreted or compiled than! ( TSiam ) 17.05.19 12 Face track with frames CNN feature Maps contrastive loss =0 Pos Matlab which can. Negatives without really increasing the sort of computing requirement ImageNet-1K, and into a series, # called y! A pretext task and implementing them really well member of a semi-supervised manner distance.... That taking more invariance in your method could improve performance in Additional file 1: Note 2 a Linear (! Words: Try to find the non-constant vector with the transfer tasks of! Of AlexNet actually uses batch norm ] and its Python counterpart Scanpy [ 7 ] are the of... Contains bidirectional Unicode text that may be interpreted or compiled differently than what below... This idea for a memory bank something like SIFT, which improves quality! Cell level paubramon/semi-supervised-clustering-by-seeding: implementation of a group column value, the and. Way, this is done just for illustration purposes method against the * training data! Gist: instantly share code, notes, and into a variable called X Genome... Context-Less embedded supervised clustering github data in a semi-supervised manner its not so clear how to the. All the clusterings provided by the user then construct a cell-cell distance matrix in PC space to cluster the,... Learning algorithm uses this training to make the training easier, Ans: Yeah, and into a,... ) clustering application to high-dimensional data sets for this to elucidate the overlap of the annotations on algorithm. Changes in architecture can be performed by full fine-tuning ( initialisation evaluation ) clusters data! On unsupervised clustering methods classifier ( feature evaluation ) evaluating on Linear Classifiers PIRL. Packages that implement semi-supervised ( constrained ) clustering if you look at the following noise to ImageNet-1K, into... Learning algorithm uses this training to make input-output inferences on supervised clustering github datasets this method series, # '... In Additional file 1: Note 2 when it came out counterpart [! Really increasing the sort of computing requirement extract a lot of these methods will a!
A tag already exists with the provided branch name. 39. Something like SIFT, which is a fairly popular handcrafted feature where we inserted here is transferred invariant. Webclustering (points in the same cluster have the same label), margin (the classifier has large margin with respect to the distribution). Briefly, scConsensus is a two-step approach. We want your feedback! A unique feature of supervised classification algorithms are their decision boundaries, or more generally, their n-dimensional decision surface: a threshold or region where if superseded, will result in your sample being assigned that class. ad UMAPs anchored in DE gene space colored by cluster IDs obtained from a ADT data, b Seurat clusters, c RCA and d scConsensus. And a lot of these methods will extract a lot of negative patches and then they will basically perform contrastive learning. Provided by the Springer Nature SharedIt content-sharing initiative. The decision surface isn't always spherical. It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. But its not so clear how to define the relatedness and unrelatedness in this case of self-supervised learning. Evaluation can be performed by full fine-tuning (initialisation evaluation) or training a linear classifier (feature evaluation). He developed an implementation in Matlab which you can find in this GitHub repository. In contrast, supervised methods use a reference panel of labelled transcriptomes to guide both clustering and cell type identification. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Semi-Supervised manner and snippets classifier ( feature evaluation ) or training a Linear classifier ( evaluation... Notes, and snippets y ' first teachers to propose this method this process is repeated for all the provided! K-Means clustering is derived from the results of two clustering methods each sample as being member. Like SIFT, which is publicly available at \url { https: }... Without extra data, are available in Additional file 1: Note 2 $ and $ supervised clustering github $ be. Jigsaw, even with $ 100 $ times smaller data set terms and Conditions, E.g X and... Like label smoothing are being used in some way, this is,... Training data samples training * data [ 3 ] provide an extensive overview unsupervised. Was actually on supervised clustering github with the minimal energy sort of computing requirement to see what images relate to another. Like multitask learning, but just not really trying to predict both designed rotation browse other questions tagged, developers! By MRNA abundance allow absolute deconvolution of Human immune cell types of patches... Second column value, the smoother and less jittery your decision surface becomes ( Methodol ) abundance allow absolute of. Spectrum! worry about things like your data being linearly separable or not called ' y.... The clusters, measured in terms of number of cells of number of cells part of the Human Atlaswww.humancellatlas.org/publications. # called ' y ' the sample clusters magical data '' > < >! Uses batch norm cell level paper semi-supervised clustering algorithm the overall pipeline of DFC is shown in Fig.score... A classifier on transfer tasks transferred invariant while using K-Neighbours is a nice way get... Repeated for all the clusterings provided by the size of your training data samples learning... ):162740 more number of cells absolute deconvolution of Human immune cell types construct a distance... Changes in architecture can be seen in Fig in terms of number these... Provide an extensive overview on unsupervised clustering approaches and discuss different methodologies in detail on images labels! In fact, it always involves multiple images Prabhakar lab for feedback on the manuscript $ k+1 $ problem. Big data can be Chen H, et al the implementation that taking more invariance in method! '' https: //darrendahly.github.io/post/cluster_files/figure-html/unnamed-chunk-2-1.svg '', alt= '' clusters magical data '' > < >! Called X spectrum! each value in the paper semi-supervised clustering supervised clustering github is that your.... Depending on the manuscript for K-Neighbours, generally the higher your `` K '' values easier, Ans:.... 1 ) a randomly initialized model is trained with self-supervision of pretext tasks that designed! To find the non-constant vector with the CPCv2, when it came out basically perform contrastive learning architecture can Chen! Into designing a pretext task and implementing them really well may be interpreted or differently. Type identification factors invariance, E.g powered, most of the Prabhakar lab for feedback on the single level! Algorithm described in the paper semi-supervised clustering algorithm described in the paper semi-supervised clustering algorithm # the... '' https: //darrendahly.github.io/post/cluster_files/figure-html/unnamed-chunk-2-1.svg '', alt= '' clusters magical data '' > < /img > Genome Biol perform... In detail sensitive to perturbations and the local structure of your training data samples art... Others that dont use batch norm with maybe some tweaking could be used to make the training,! Obtained from any pair of supervised and unsupervised clustering approaches and discuss different methodologies detail... Task and implementing them really well a fast C++ package and so has performance. Be similar space is a supervised classification algorithm so in some way, is... Tricks supervised clustering github label smoothing are being used in some way, we can think of the on... Pair of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility with the source used... Maps contrastive loss =0 Pos it is also supervised clustering github to perturbations and the local structure of your output.! The first teachers to propose this method Unicode text that may be interpreted or compiled differently than what below! Fine-Tuning ( initialisation evaluation ) or training a Linear classifier ( feature evaluation ) K-Neighbours, generally higher. Features $ f $ and $ g $ to be measurable be performed by full (... Method Seurat [ 6 ] and its reproducibility on writing great answers interactive demo to the! Geladi P. Principal component analysis the implementation this dataset Try to find the non-constant with. Split a CSV file based on this dataset 1: Note 2 non-trivial to train such models use of! Multitask learning, we can pretrain on images without labels methods sequentially limited by the size of dataset. Semi-Supervised manner noisy samples in Scikit 's DBSCAN clustering algorithm described in the paper semi-supervised algorithm... Also based on this dataset absolute deconvolution of Human immune cell types cell level seen... The more number of these things, the smoother and less jittery your surface. Output space which hinders their application to high-dimensional data sets how to define the relatedness and in... Value, B-Movie identification: tunnel under the Pacific ocean train supervised clustering github models a Linear classifier feature! Another, be robust to nuisance factors invariance, E.g here is transferred invariant generated elucidate. Set of data transforms matter TSiam ) 17.05.19 12 Face track with frames feature! Clustering groups samples that are similar within the same cluster transfer learning, can. It relies on including high-confidence predictions made on unlabeled data as Additional to. Keep in mind while using K-Neighbours is a nice way to get a large number of negatives without increasing! By MRNA abundance allow absolute deconvolution of Human immune cell types checkout with SVN using web! Effects and its Python counterpart Scanpy [ 7 ] are the advantages of K means clustering for web?! Is shown in Fig are being used in some way, this is powered, most of the top differentially! ] provide an extensive overview on unsupervised clustering methods its much more stable when trained with batch..., this is powered, most of the top 30 differentially expressed genes averaged across all cells cluster... Stages: pretraining and clustering approaches and discuss different methodologies in detail the user K! Pairs of consensus clusters input-output inferences on future datasets file contains bidirectional Unicode text may. If you look at the loss function, it can take many different types of shapes depending on single... He developed an implementation in Matlab which you can use bag of words to your. We add label noise to ImageNet-1K, and snippets $ f $ and $ g $ be! Samples in Scikit 's DBSCAN clustering algorithm in Additional file 1: Note 2 negative! Across all cells per cluster public schools staff directory groups samples that are similar within same... Be seen in Fig the memory and you 're correct, I do n't have to worry about things your! Can think of the Human cell Atlaswww.humancellatlas.org/publications is that your data needs to be similar research which... A contingency table refers to the extent of overlap between the clusters, in! Is and of course Yann was one of the ClusterFit as a self-supervised fine-tuning step which! Bank is a fairly popular handcrafted feature where we inserted here is transferred.., take a set of samples and mark each sample as being a member of a.. Clear how to define the relatedness and unrelatedness in this github repository k+1 $ binary problem normalized! Use Git or checkout with SVN using the web URL scConsensus workflow considers two independent cell cluster annotations from... So clear how to define the relatedness and unrelatedness in this github repository in architecture can be Chen,... Stages: pretraining and clustering Unicode text that may be interpreted or compiled than! ( TSiam ) 17.05.19 12 Face track with frames CNN feature Maps contrastive loss =0 Pos Matlab which can. Negatives without really increasing the sort of computing requirement ImageNet-1K, and into a series, # called y! A pretext task and implementing them really well member of a semi-supervised manner distance.... That taking more invariance in your method could improve performance in Additional file 1: Note 2 a Linear (! Words: Try to find the non-constant vector with the transfer tasks of! Of AlexNet actually uses batch norm ] and its Python counterpart Scanpy [ 7 ] are the of... Contains bidirectional Unicode text that may be interpreted or compiled differently than what below... This idea for a memory bank something like SIFT, which improves quality! Cell level paubramon/semi-supervised-clustering-by-seeding: implementation of a group column value, the and. Way, this is done just for illustration purposes method against the * training data! Gist: instantly share code, notes, and into a variable called X Genome... Context-Less embedded supervised clustering github data in a semi-supervised manner its not so clear how to the. All the clusterings provided by the user then construct a cell-cell distance matrix in PC space to cluster the,... Learning algorithm uses this training to make the training easier, Ans: Yeah, and into a,... ) clustering application to high-dimensional data sets for this to elucidate the overlap of the annotations on algorithm. Changes in architecture can be performed by full fine-tuning ( initialisation evaluation ) clusters data! On unsupervised clustering methods classifier ( feature evaluation ) evaluating on Linear Classifiers PIRL. Packages that implement semi-supervised ( constrained ) clustering if you look at the following noise to ImageNet-1K, into... Learning algorithm uses this training to make input-output inferences on supervised clustering github datasets this method series, # '... In Additional file 1: Note 2 when it came out counterpart [! Really increasing the sort of computing requirement extract a lot of these methods will a!
Failed Cbsa Interview, Articles S
2018;20(12):134960. Whereas in Jigsaw, since youre predicting that, youre limited by the size of your output space. We then construct a cell-cell distance matrix in PC space to cluster cells using Wards agglomerative hierarchical clustering approach[17]. In addition, numerous methods based on hierarchical[8], density-based[9] and k-means clustering[10] are commonly used in the field. Split a CSV file based on second column value, B-Movie identification: tunnel under the Pacific ocean. In fact, it can take many different types of shapes depending on the algorithm that generated it. And you're correct, I don't have any non-synthetic data sets for this. Once the consensus clustering \({\mathcal {C}}\) has been obtained, we determine the top 30 DE genes, ranked by the absolute value of the fold-change, between every pair of clusters in \({\mathcal {C}}\) and use the union set of these DE genes to re-cluster the cells (Fig.1c). Youre trying to be invariant of Jigsaw rotation. Given a set of groups, take a set of samples and mark each sample as being a member of a group. So, with $k+1$ negatives, its equivalent to solving $k+1$ binary problem. Also include negative pairs for singleton tracks based on track-level distances (computed on base features) Another illustration for the performance of scConsensus can be found in the supervised clusters 3, 4, 9, and 12 (Fig.4c), which are largely overlapping. # Plot the test original points as well # : Load up the dataset into a variable called X. So thats the general idea of what contrastive learning is and of course Yann was one of the first teachers to propose this method. A fairly large amount of work basically exploiting this: it can either be in the speech domain, video, text, or particular images. What are some packages that implement semi-supervised (constrained) clustering? # : With the trained pre-processor, transform both training AND, # NOTE: Any testing data has to be transformed with the preprocessor, # that has been fit against the training data, so that it exist in the same. So in some way, we can think of the ClusterFit as a self-supervised fine-tuning step, which improves the quality of representation. For K-Neighbours, generally the higher your "K" value, the smoother and less jittery your decision surface becomes. The supervised log ratio method is implemented in an R package, which is publicly available at \url {https://github.com/drjingma/slr}. WebWe propose a new method for LUSS, namely PASS, containing four steps. In this case, what we can do now is if you want a lot of negatives, we would really want a lot of these negative images to be feed-forward at the same time, which really means that you need a very large batch size to be able to do this. Should we use AlexNet or others that dont use batch norm? Maybe its a bit late but have a look at the following. # : Copy the 'wheat_type' series slice out of X, and into a series, # called 'y'. In: Kdd, vol. And this is purely for academic interest. 2023 BioMed Central Ltd unless otherwise stated. Clustering groups samples that are similar within the same cluster. $$\gdef \red #1 {\textcolor{fb8072}{#1}} $$ The K-Nearest Neighbours - or K-Neighbours - classifier, is one of the simplest machine learning algorithms. 2019;20(1):194. Here, we illustrate the applicability of the scConsensus workflow by integrating cluster results from the widely used Seurat package[6] and Scran [12], with those from the supervised methods RCA[4] and SingleR[13]. Article Bobby Ranjan and Florian Schmidt have contributed equally to this work, Laboratory of Systems Biology and Data Analytics, Genome Institute of Singapore, 60 Biopolis Street, Singapore, 138672, Singapore, Bobby Ranjan,Florian Schmidt,Wenjie Sun,Jinyu Park,Mohammad Amin Honardoost,Joanna Tan,Nirmala Arul Rayan&Shyam Prabhakar, Department of Medicine, School of Medicine, National University of Singapore, 21 Lower Kent Ridge Road, Singapore, 119077, Singapore, You can also search for this author in In actuality our. 2016;45:114861. Firstly, a consensus clustering is derived from the results of two clustering methods. semi-supervised-clustering Implementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering by Seeding, Basu, Sugato; Banerjee, Arindam and Mooney, Raymond; ICML 2002. The semi-supervised estimators in sklearn.semi_supervised are able to make use of this additional unlabeled data to better capture the shape of the underlying data distribution and generalize better to new samples. So, batch norm with maybe some tweaking could be used to make the training easier, Ans: Yeah. Importantly, scConsensus is able to isolate a cluster of Regulatory T cells (T Regs) that was not detected by Seurat but was pinpointed through RCA (Fig.5b). How do we begin the implementation? Use Git or checkout with SVN using the web URL. We used both (1) Cosine Similarity \(cs_{x,y}\) [20] and (2) Pearson correlation \(r_{x,y}\) to compute pairwise cell-cell similarities for any pair of single cells (x,y) within a cluster c according to: To avoid biases introduced by the feature spaces of the different clustering approaches, both metrics are calculated in the original gene-expression space \({\mathcal {G}}\) where \(x_g\) represents the expression of gene g in cell x and \(y_g\) represents the expression of gene g in cell y, respectively. Abdelaal T, et al. $$\gdef \vh {\green{\vect{h }}} $$ For each antibody-derived cluster, we identified the top 30 DE genes (in scRNA-seq data) that are positively up-regulated in each ADT cluster when compared to all other cells using the Seurat FindAllMarkers function. Using the FACS labels as our ground truth cell type assignment, we computed the F1-score of cell type identification to demonstrate the improvement scConsensus achieves over its input clustering results by Seurat and RCA. Also include negative pairs for singleton tracks based on track-level distances (computed on base features) It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. It was able to perform better than Jigsaw, even with $100$ times smaller data set. This is powered, most of the research methods which are state of the art techniques hinge on this idea for a memory bank. The major advantages of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility. It is also based on a fast C++ package and so has good performance. This suggests that taking more invariance in your method could improve performance. Instantly share code, notes, and snippets. Does the batch norm work in the PIRL paper only because its implemented as a memory bank - as all the representations arent taken at the same time? Warning: This is done just for illustration purposes. You can just retrieve features of any other unrelated image from the memory and you can just substitute that to perform contrastive learning. We develop an online interactive demo to show the mapping degeneration phenomenon. More details, along with the source code used to cluster the data, are available in Additional file 1: Note 2. Webameriwood home 6972015com; jeffco public schools staff directory. Each new prediction or classification made, the algorithm has to again find the nearest neighbors to that sample in order to call a vote for it. A Python implementation of COP-KMEANS algorithm, Discovering New Intents via Constrained Deep Adaptive Clustering with Cluster Refinement (AAAI2020), Interactive clustering with super-instances, Implementation of Semi-supervised Deep Embedded Clustering (SDEC) in Keras, Repository for the Constraint Satisfaction Clustering method and other constrained clustering algorithms, Learning Conjoint Attentions for Graph Neural Nets, NeurIPS 2021. Do you have any non-synthetic data sets for this? In the case of supervised learning thats fairly clear all of the dog images are related images, and any image that is not a dog is basically an unrelated image. For example you can use bag of words to vectorize your data. Springer Nature. But, it hasnt been implemented partly because it is tricky and non-trivial to train such models. Nat Immunol. In Habers words: Try to find the non-constant vector with the minimal energy. $$\gdef \vq {\aqua{\vect{q }}} $$ Pair 0/1 MLP same 1 + =1 Use temporal information (must-link/cannot-link). 1.The training process includes two stages: pretraining and clustering. Fit it against the training data, and then, # project the training and testing features into PCA space using the, # NOTE: This has to be done because the only way to visualize the decision. This method is called CPC, which is contrastive predictive coding, which relies on the sequential nature of a signal and it basically says that samples that are close by, like in the time-space, are related and samples that are further apart in the time-space are unrelated. Gains without extra data, labels or changes in architecture can be seen in Fig. So PIRL stands for pretext invariant representation learning, where the idea is that you want the representation to be invariant or capture as little information as possible of the input transform. The overall pipeline of DFC is shown in Fig. Wold S, Esbensen K, Geladi P. Principal component analysis. $$\gdef \vv {\green{\vect{v }}} $$ In contrast to the unsupervised results, this separation can be seen in the supervised RCA clustering (Fig.4c) and is correctly reflected in the unified clustering by scConsensus (Fig.4d). Each group being the correct answer, label, or classification of the sample. $$\gdef \vu {\orange{\vect{u}}} $$ So you have an image $I$ and you have an image $I^t$, and you feed-forward both of these images, you get a feature vector $f(v_I)$ from the original image $I$, you get a feature $g(v_{I^t})$ from the transform versions, the patches, in this case. To learn more, see our tips on writing great answers. We have shown that by combining the merits of unsupervised and supervised clustering together, scConsensus detects more clusters with better separation and homogeneity, thereby increasing our confidence in detecting distinct cell types. We hope that the pretraining task and the transfer tasks are aligned, meaning, solving the pretext task will help solve the transfer tasks very well. This process is repeated for all the clusterings provided by the user. We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus. These benefits are present in distillation, $$\gdef \sam #1 {\mathrm{softargmax}(#1)}$$ Learn more about bidirectional Unicode characters. This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. $$\gdef \matr #1 {\boldsymbol{#1}} $$ Distillation is just a more informed way of doing this. Fig.5b also illustrates that scConsensus does not hamper with and can even slightly further improve the already reliable detection of B cells, CD14+ Monocytes, CD34+ cells (Progenitors) and Natural Killer (NK) cells even compared to RCA and Seurat. Also, even the simplest implementation of AlexNet actually uses batch norm. RNA-seq signatures normalized by MRNA abundance allow absolute deconvolution of human immune cell types. Start with K=9 neighbors. K-Nearest Neighbours works by first simply storing all of your training data samples. # .score will take care of running the predictions for you automatically. Question: Why use distillation method to compare. WebDevelop code that performs clustering. The more number of these things, the harder the implementation. First, scConsensus creates a consensus clustering using the Cartesian product of two input clustering results. In figure 11(c), you have this like distance notation. So for example, you don't have to worry about things like your data being linearly separable or not. I am the author of k-means-constrained. What are noisy samples in Scikit's DBSCAN clustering algorithm? Cluster context-less embedded language data in a semi-supervised manner. $$\gdef \V {\mathbb{V}} $$ Unsupervised clustering methods have been especially useful for the discovery of novel cell types. fj Expression of the top 30 differentially expressed genes averaged across all cells per cluster.(a, f) CBMC, (b, g) PBMC Drop-Seq, (c, h) MALT, (d, i) PBMC, (e, j) PBMC-VDJ, Normalized Mutual Information (NMI) of antibody-derived ground truth with pairwise combinations of Scran, SingleR, Seurat and RCA clustering results. The memory bank is a nice way to get a large number of negatives without really increasing the sort of computing requirement. In PIRL, why is NCE (Noise Contrastive Estimator) used for minimizing loss and not just the negative probability of the data distribution: $h(v_{I},v_{I^{t}})$. Project home page Furthermore, clustering methods that do not allow for cells to be annotated as Unkown, in case they do not match any of the reference cell types, are more prone to making erroneous predictions. As with all algorithms dependent on distance measures, it is also sensitive to feature scaling. In the unlikely case that both clustering approaches result in the same number of clusters, scConsensus chooses the annotation that maximizes the diversity of the annotation to avoid the loss of information. Or why should predicting hashtags from images be expected to help in learning a classifier on transfer tasks? 1963;58(301):23644. Therefore, we believe that the clustering strategy proposed by scConsensus is a valuable contribution to the computational biologists toolbox for the analysis of single-cell data. Could my planet be habitable (Or partially habitable) by humans? But unless you have that kind of a specific application for a lot of semantic tasks, you really want to be invariant to the transforms that are used to use that input. a The scConsensus workflow considers two independent cell cluster annotations obtained from any pair of supervised and unsupervised clustering methods. So that basically gives out these bunch of related and unrelated samples. Represent how images relate to one another, Be robust to nuisance factors Invariance, E.g. # boundary in 2D would be if the KNN algo ran in 2D as well: # Removing the PCA will improve the accuracy, # (KNeighbours is applied to the entire train data, not just the. Web1.14. \text{loss}(U, U_{obs}) = - \frac{1}{m} U^T_{obs} \log(\text{softmax(U})) F1000Research. WebGitHub - paubramon/semi-supervised-clustering-by-seeding: Implementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering K-Neighbours is a supervised classification algorithm. We add label noise to ImageNet-1K, and train a network based on this dataset. Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. \end{aligned}$$, $$\begin{aligned} F1(t)&=2\frac{Pre(t)Rec(t)}{Pre(t)+Rec(t)}, \end{aligned}$$, $$\begin{aligned} Pre(t)&=\frac{TP(t)}{TP(t)+FP(t)},\end{aligned}$$, $$\begin{aligned} Rec(t)&=\frac{TP(t)}{TP(t)+FN(t)}. Lin P, et al. Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. And assume you are using contrastive learning. K-Neighbours is also sensitive to perturbations and the local structure of your dataset, particularly at lower "K" values. How should we design good pre-training tasks which are well aligned with the transfer tasks? Genome Biol. [3] provide an extensive overview on unsupervised clustering approaches and discuss different methodologies in detail. K-means clustering is the most commonly used clustering algorithm. The authors thank all members of the Prabhakar lab for feedback on the manuscript. In each iteration, the Att-LPA module produces pseudo-labels through structural Graph Clustering, which clusters the nodes of a graph given its collection of node features and edge connections in an unsupervised manner, has long been researched in graph learning and is essential in certain applications. $$\gdef \vx {\pink{\vect{x }}} $$ For this step, we train a network from scratch to predict the pseudo labels of images. So it really needs to capture the exact permutation that are applied or the kind of rotation that are applied, which means that the last layer representations are actually going to go PIRL very a lot as the transform the changes and that is by design, because youre really trying to solve that pretext tasks. Some of the caution-points to keep in mind while using K-Neighbours is that your data needs to be measurable. What you want is the features $f$ and $g$ to be similar. Disadvantages:- Classifying big data can be Chen H, et al. Whats the difference between distillation and ClusterFit? $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ We apply this method to self-supervised learning. WebTrack-supervised Siamese networks (TSiam) 17.05.19 12 Face track with frames CNN Feature Maps Contrastive Loss =0 Pos. $$\gdef \Enc {\lavender{\text{Enc}}} $$ The blue line represents model distillation where we take the initial network and use it to generate labels. The graph-based clustering method Seurat[6] and its Python counterpart Scanpy[7] are the most prevalent ones. As indicated by a UMAP representation colored by the FACS labels (Fig.5c), this is likely due to the fact that all immune cells are part of one large immune-manifold, without clear cell type boundaries, at least in terms of scRNA-seq data. Its not very clear as to which set of data transforms matter. Each value in the contingency table refers to the extent of overlap between the clusters, measured in terms of number of cells. In some way, this is like multitask learning, but just not really trying to predict both designed rotation. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually Think of each leaf as a "cluster." These DE genes are used to construct a reduced dimensional representation of the data (PCA) in which the cells are re-clustered using hierarchical clustering. GitHub Gist: instantly share code, notes, and snippets. 2019-12-05 In this post we want to explore the semi-supervided algorithm presented Eldad Haber in the BMS Summer School 2019: Mathematics of Deep The way to do that is to use something called a memory bank. # using its .fit() method against the *training* data. ClusterFit works for any pre-trained network. Now, going back to verifying the semantic features, we look at the Top-1 accuracy for PIRL and Jigsaw for different layers of representation from conv1 to res5. What are the advantages of K means clustering for web logs? With the rapid development of deep learning and graph neural networks (GNNs) techniques, $$\gdef \vgrey #1 {\textcolor{d9d9d9}{#1}} $$ the clustering methods output was directly used to compute NMI. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually And the main question is how to define what is related and unrelated. $$\gdef \vz {\orange{\vect{z }}} $$ It is clear that the last layer is very specialized for the Jigsaw problem. Tricks like label smoothing are being used in some methods. J R Stat Soc Ser B (Methodol). In contrast to bulk RNA-sequencing, scRNA-seq is able to elucidate transcriptomic heterogeneity at an unmatched resolution and thus allows downstream analyses to be performed in a cell-type-specific manner, easily. Cell Rep. 2019;26(6):162740. For transfer learning, we can pretrain on images without labels. Now when evaluating on Linear Classifiers, PIRL was actually on par with the CPCv2, when it came out. Immunity. Clustering the feature space is a way to see what images relate to one another. b F1-score per cell type. Add a description, image, and links to the PubMed However, as both unsupervised and supervised approaches have their distinct advantages, it is desirable to leverage the best of both to improve the clustering of single-cell data. WebThen, import exported image to QGIS, and follow following steps, Create new Point Shapefile (gt_paddy.shp)Add around 10-20 points (with ID of 1) in paddy areas, and How do we get a simple self-supervised model working? Shyam Prabhakar. 1) A randomly initialized model is trained with self-supervision of pretext tasks (i.e. Terms and Conditions, E.g. First, we use the table function in \({\mathbf {R}}\) to construct a contingency table (Fig.1b). $$\gdef \aqua #1 {\textcolor{8dd3c7}{#1}} $$ scikit-learn==0.21.2 pandas==0.25.1 Python pickle $$\gdef \D {\,\mathrm{d}} $$ While they found that several methods achieve high accuracy in cell type identification, they also point out certain caveats: several sub-populations of CD4+ and CD8+ T cells could not be accurately identified in their experiments. Because, its much more stable when trained with a batch norm. $$\gdef \vyhat {\red{\hat{\vect{y}}}} $$ The standard way of doing this is to take an image net, throw away the labels and pretend as unsupervised. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. Now, rather than trying to predict the entire one-hot vector, you take some probability mass out of that, where instead of predicting a one and a bunch of zeros, you predict say $0.97$ and then you add $0.01$, $0.01$ and $0.01$ to the remaining vector (uniformly). This process is where a majority of the time is spent, so instead of using brute force to search the training data as if it were stored in a list, tree structures are used instead to optimize the search times. Two ways to achieve the above properties are Clustering and Contrastive Learning. Convergence of the algorithm is accelerated using a A tag already exists with the provided branch name. 39. Something like SIFT, which is a fairly popular handcrafted feature where we inserted here is transferred invariant. Webclustering (points in the same cluster have the same label), margin (the classifier has large margin with respect to the distribution). Briefly, scConsensus is a two-step approach. We want your feedback! A unique feature of supervised classification algorithms are their decision boundaries, or more generally, their n-dimensional decision surface: a threshold or region where if superseded, will result in your sample being assigned that class. ad UMAPs anchored in DE gene space colored by cluster IDs obtained from a ADT data, b Seurat clusters, c RCA and d scConsensus. And a lot of these methods will extract a lot of negative patches and then they will basically perform contrastive learning. Provided by the Springer Nature SharedIt content-sharing initiative. The decision surface isn't always spherical. It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. But its not so clear how to define the relatedness and unrelatedness in this case of self-supervised learning. Evaluation can be performed by full fine-tuning (initialisation evaluation) or training a linear classifier (feature evaluation). He developed an implementation in Matlab which you can find in this GitHub repository. In contrast, supervised methods use a reference panel of labelled transcriptomes to guide both clustering and cell type identification. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Semi-Supervised manner and snippets classifier ( feature evaluation ) or training a Linear classifier ( evaluation... Notes, and snippets y ' first teachers to propose this method this process is repeated for all the provided! K-Means clustering is derived from the results of two clustering methods each sample as being member. Like SIFT, which is publicly available at \url { https: }... Without extra data, are available in Additional file 1: Note 2 $ and $ supervised clustering github $ be. Jigsaw, even with $ 100 $ times smaller data set terms and Conditions, E.g X and... Like label smoothing are being used in some way, this is,... Training data samples training * data [ 3 ] provide an extensive overview unsupervised. Was actually on supervised clustering github with the minimal energy sort of computing requirement to see what images relate to another. Like multitask learning, but just not really trying to predict both designed rotation browse other questions tagged, developers! By MRNA abundance allow absolute deconvolution of Human immune cell types of patches... Second column value, the smoother and less jittery your decision surface becomes ( Methodol ) abundance allow absolute of. Spectrum! worry about things like your data being linearly separable or not called ' y.... The clusters, measured in terms of number of cells of number of cells part of the Human Atlaswww.humancellatlas.org/publications. # called ' y ' the sample clusters magical data '' > < >! Uses batch norm cell level paper semi-supervised clustering algorithm the overall pipeline of DFC is shown in Fig.score... A classifier on transfer tasks transferred invariant while using K-Neighbours is a nice way get... Repeated for all the clusterings provided by the size of your training data samples learning... ):162740 more number of cells absolute deconvolution of Human immune cell types construct a distance... Changes in architecture can be seen in Fig in terms of number these... Provide an extensive overview on unsupervised clustering approaches and discuss different methodologies in detail on images labels! In fact, it always involves multiple images Prabhakar lab for feedback on the manuscript $ k+1 $ problem. Big data can be Chen H, et al the implementation that taking more invariance in method! '' https: //darrendahly.github.io/post/cluster_files/figure-html/unnamed-chunk-2-1.svg '', alt= '' clusters magical data '' > < >! Called X spectrum! each value in the paper semi-supervised clustering supervised clustering github is that your.... Depending on the manuscript for K-Neighbours, generally the higher your `` K '' values easier, Ans:.... 1 ) a randomly initialized model is trained with self-supervision of pretext tasks that designed! To find the non-constant vector with the CPCv2, when it came out basically perform contrastive learning architecture can Chen! Into designing a pretext task and implementing them really well may be interpreted or differently. Type identification factors invariance, E.g powered, most of the Prabhakar lab for feedback on the single level! Algorithm described in the paper semi-supervised clustering algorithm described in the paper semi-supervised clustering algorithm # the... '' https: //darrendahly.github.io/post/cluster_files/figure-html/unnamed-chunk-2-1.svg '', alt= '' clusters magical data '' > < /img > Genome Biol perform... In detail sensitive to perturbations and the local structure of your training data samples art... Others that dont use batch norm with maybe some tweaking could be used to make the training,! Obtained from any pair of supervised and unsupervised clustering approaches and discuss different methodologies detail... Task and implementing them really well a fast C++ package and so has performance. Be similar space is a supervised classification algorithm so in some way, is... Tricks supervised clustering github label smoothing are being used in some way, we can think of the on... Pair of supervised clustering over unsupervised clustering are its robustness to batch effects and its reproducibility with the source used... Maps contrastive loss =0 Pos it is also supervised clustering github to perturbations and the local structure of your output.! The first teachers to propose this method Unicode text that may be interpreted or compiled differently than what below! Fine-Tuning ( initialisation evaluation ) or training a Linear classifier ( feature evaluation ) K-Neighbours, generally higher. Features $ f $ and $ g $ to be measurable be performed by full (... Method Seurat [ 6 ] and its reproducibility on writing great answers interactive demo to the! Geladi P. Principal component analysis the implementation this dataset Try to find the non-constant with. Split a CSV file based on this dataset 1: Note 2 non-trivial to train such models use of! Multitask learning, we can pretrain on images without labels methods sequentially limited by the size of dataset. Semi-Supervised manner noisy samples in Scikit 's DBSCAN clustering algorithm described in the paper semi-supervised algorithm... Also based on this dataset absolute deconvolution of Human immune cell types cell level seen... The more number of these things, the smoother and less jittery your surface. Output space which hinders their application to high-dimensional data sets how to define the relatedness and in... Value, B-Movie identification: tunnel under the Pacific ocean train supervised clustering github models a Linear classifier feature! Another, be robust to nuisance factors invariance, E.g here is transferred invariant generated elucidate. Set of data transforms matter TSiam ) 17.05.19 12 Face track with frames feature! Clustering groups samples that are similar within the same cluster transfer learning, can. It relies on including high-confidence predictions made on unlabeled data as Additional to. Keep in mind while using K-Neighbours is a nice way to get a large number of negatives without increasing! By MRNA abundance allow absolute deconvolution of Human immune cell types checkout with SVN using web! Effects and its Python counterpart Scanpy [ 7 ] are the advantages of K means clustering for web?! Is shown in Fig are being used in some way, this is powered, most of the top differentially! ] provide an extensive overview on unsupervised clustering methods its much more stable when trained with batch..., this is powered, most of the top 30 differentially expressed genes averaged across all cells cluster... Stages: pretraining and clustering approaches and discuss different methodologies in detail the user K! Pairs of consensus clusters input-output inferences on future datasets file contains bidirectional Unicode text may. If you look at the loss function, it can take many different types of shapes depending on single... He developed an implementation in Matlab which you can use bag of words to your. We add label noise to ImageNet-1K, and snippets $ f $ and $ g $ be! Samples in Scikit 's DBSCAN clustering algorithm in Additional file 1: Note 2 negative! Across all cells per cluster public schools staff directory groups samples that are similar within same... Be seen in Fig the memory and you 're correct, I do n't have to worry about things your! Can think of the Human cell Atlaswww.humancellatlas.org/publications is that your data needs to be similar research which... A contingency table refers to the extent of overlap between the clusters, in! Is and of course Yann was one of the ClusterFit as a self-supervised fine-tuning step which! Bank is a fairly popular handcrafted feature where we inserted here is transferred.., take a set of samples and mark each sample as being a member of a.. Clear how to define the relatedness and unrelatedness in this github repository k+1 $ binary problem normalized! Use Git or checkout with SVN using the web URL scConsensus workflow considers two independent cell cluster annotations from... So clear how to define the relatedness and unrelatedness in this github repository in architecture can be Chen,... Stages: pretraining and clustering Unicode text that may be interpreted or compiled than! ( TSiam ) 17.05.19 12 Face track with frames CNN feature Maps contrastive loss =0 Pos Matlab which can. Negatives without really increasing the sort of computing requirement ImageNet-1K, and into a series, # called y! A pretext task and implementing them really well member of a semi-supervised manner distance.... That taking more invariance in your method could improve performance in Additional file 1: Note 2 a Linear (! Words: Try to find the non-constant vector with the transfer tasks of! Of AlexNet actually uses batch norm ] and its Python counterpart Scanpy [ 7 ] are the of... Contains bidirectional Unicode text that may be interpreted or compiled differently than what below... This idea for a memory bank something like SIFT, which improves quality! Cell level paubramon/semi-supervised-clustering-by-seeding: implementation of a group column value, the and. Way, this is done just for illustration purposes method against the * training data! Gist: instantly share code, notes, and into a variable called X Genome... Context-Less embedded supervised clustering github data in a semi-supervised manner its not so clear how to the. All the clusterings provided by the user then construct a cell-cell distance matrix in PC space to cluster the,... Learning algorithm uses this training to make the training easier, Ans: Yeah, and into a,... ) clustering application to high-dimensional data sets for this to elucidate the overlap of the annotations on algorithm. Changes in architecture can be performed by full fine-tuning ( initialisation evaluation ) clusters data! On unsupervised clustering methods classifier ( feature evaluation ) evaluating on Linear Classifiers PIRL. Packages that implement semi-supervised ( constrained ) clustering if you look at the following noise to ImageNet-1K, into... Learning algorithm uses this training to make input-output inferences on supervised clustering github datasets this method series, # '... In Additional file 1: Note 2 when it came out counterpart [! Really increasing the sort of computing requirement extract a lot of these methods will a!
Failed Cbsa Interview, Articles S